

Info alert:Important Notice
Please note that more information about the previous v2 releases can be found here. You can use "Find a release" search bar to search for a particular release.
Working with machine learning features
Table of Contents
Feature Store provides an interface between machine learning models and data.
Overview of machine learning features and Feature Store
A machine learning (ML) feature is a measurable property or attribute within a data set that a machine learning model can analyze to learn patterns and make decisions. Examples of features include a customer’s purchase history, demographic data like age and location, weather conditions, and financial market data. You can use these features to train models for tasks such as personalized product recommendations, fraud detection, and predictive maintenance.
Feature Store is a Open Data Hub component that provides a centralized repository that stores, manages, and serves machine learning features for both training and inference purposes.
Audience for Feature Store
The target audience for Feature Store is ML platform and MLOps teams with DevOps experience in deploying real-time models to production. Feature Store also helps these teams build a feature platform that improves collaboration between data engineers, software engineers, machine learning engineers, and data scientists.
- For Data Scientists
-
Feature Store is a tool where you can define, store, and retrieve your features for both model development and model deployment. By using Feature Store, you can focus on what you do best: build features that power your AI/ML models and maximize the value of your data.
- For MLOps Engineers
-
Feature Store is a library that connects your existing infrastructure, such as online database, application server, microservice, analytical database, and orchestration tooling. By using Feature Store, you can focus on maintaining a resilient system, instead of implementing features for data scientists.
- For Data Engineers
-
Feature Store provides a centralized catalog for storing feature definitions, allowing you to maintain a single source of truth for feature data. It provides the abstraction for reading and writing to many different types of offline and online data stores. Using the provided Python SDK or the feature server service, you can write data to the online and offline stores and then read out that data in either batch scenarios for model training or low-latency online scenarios for model inference.
- For AI Engineers
-
Feature Store provides a platform designed to scale your AI applications by enabling seamless integration of richer data and facilitating fine-tuning. With Feature Store, you can optimize the performance of your AI models while ensuring a scalable and efficient data pipeline.
Overview of machine learning features
In machine learning, a feature, also referred to as a field, is an individual measurable property. A feature is used as an input signal to a predictive model. For example, if a bank’s loan department is trying to predict whether an applicant should be approved for a loan, a useful feature might be whether they have filed for bankruptcy in the past or how much credit card debt they currently carry.
customer_id |
avg_cc_balance |
credit_score |
bankruptcy |
1005 |
500.00 |
730 |
0 |
982 |
20000.00 |
570 |
2 |
1001 |
1400.00 |
600 |
0 |
Features are prepared data that help machine learning models understand patterns in the world. Feature engineering is the process of selecting, manipulating, and transforming raw data into features that can be used in supervised learning. As shown in the table, a feature refers to an entire column in a dataset, for example, credit_score. A feature value refers to a single value in a feature column, such as 730.
Overview of Feature Store
Feature Store is an Open Data Hub component that provides an interface between models and data. It is based on the Feast open source project. Feature Store provides a framework for storing, managing, and serving features to machine learning models by using your existing infrastructure and data stores. It facilitates the retrieval of feature data from different data sources to generate and manage features by providing unified feature management capabilities.
The following figure shows where Feature Store fits in the ML workflow. In an ML workflow, features are inputs to ML models. The ML workflow starts with many types of relevant data, such as transactional data, customer references, and product data. The data comes from a variety of databases and data sources. From this data, ML engineers use Feature Store to curate features. The features are input to models and the models can then use the data from the features to make predictions.
Figure 1. Feature Store in the ML workflow
Feature Store is a machine learning data system that provides the following capabilities:
-
Runs data pipelines that transform raw data into feature values
-
Stores and manages feature data
-
Serves feature data consistently for training and inference purposes
-
Manages features consistently across offline and online environments
-
Powers one model or thousands simultaneously with fresh, reusable features, on demand
Feature Store is a centralized hub for storing, processing, and accessing commonly-used features that enables users in your ML organization to collaborate. When you register a feature in a Feature Store, it becomes available for immediate reuse by other models across your organization. The Feature Store registry reduces duplication of data engineering efforts and allows new ML projects to bootstrap with a library of curated, production-ready features.
Feature Store provides consistency in model training and inference, promotes collaboration and usability across multiple projects, monitors lineage and versioning of models for data drifts, leaks, and training skews, and seamlessly integrates with other MLOps tools. Feature Store remotely manages data stored in other systems, such as BigQuery, Snowflake, DynamoDB, and Redis, to make features consistently available at training / serving time.
Feature Store performs the following tasks:
-
Stores features in offline and online stores
-
Registers features in the registry for sharing
-
Serves features to ML models
ML platform teams use Feature Store to store and serve features consistently for offline training, such as batch-scoring, and online real-time model inference.
Feature Store consists of the following key components:
- Registry
-
A central catalog of all feature definitions and their related metadata. It allows ML engineers and data scientists to search, discover, and collaborate on new features. The registry exposes methods to apply, list, retrieve, and delete features.
- Offline Store
-
The data store that contains historical data for scale-out batch scoring or model training. The offline store persists batch data that has been ingested into Feature Store. This data is used for producing training datasets. Examples of offline stores include Dask, Snowflake, BigQuery, Redshift, and DuckDB.
- Online Store
-
The data store that is used for low-latency feature retrieval. The online store is used for real-time inference. Examples of online stores include Redis, GCP Datastore, and DynamoDB.
- Server
-
A feature server that serves pre-computed features online. There are three Feature Store servers:
-
The online feature server - A Python feature server that is an HTTP endpoint that serves features with JSON I/O. You can write and read features from the online store using any programming language that can make HTTP requests.
-
The offline feature server - An Apache Arrow Flight Server that uses the gRPC communication protocol to exchange data. This server wraps calls to existing offline store implementations and exposes interfaces as Arrow Flight endpoints.
-
The registry server - A server that uses the gRPC communication protocol to exchange data. You can communicate with the server using any programming language that can make gRPC requests.
-
- UI
-
A web-based graphical user interface (UI) for viewing all the Feature Store objects and their relationships with each other.
Feature Store provides the following software capabilities:
-
A Python SDK for programmatically defining features and data sources
-
A Python SDK for reading and writing features to offline and online data stores
-
An optional feature server for reading and writing features (useful for non-python languages) by using APIs
-
A web-based UI for viewing and exploring information about features defined in the project
-
A command line interface (CLI) for viewing and updating feature information
Feature Store workflow
The Feature Store workflow involves the following tasks OpenShift cluster administrators, and machine learning (ML) engineers or data scientists:
Note: This Feature Store workflow describes a local implementation that is available in this Technology Preview release.
Cluster administrator
Installs and configures Feature Store, as described in Chapter 2. Configuring Feature Store:
-
Installs OpenShift AI.
-
Enables the Feature Store component by using the Feature Store operator.
-
Creates a project.
-
In the project, creates a Feature Store instance by using a
feast.yamlfile that specifies the offline and online stores. -
Sets up Feature Store so that ML Engineers and data scientists can push and retrieve features to use for model training and inference.
ML Engineer or data scientist
-
Prepares features, as described in Chapter 3: Defining features:
-
Creates a feature definition file.
-
Defines the data sources and other Feature Store objects.
-
Makes features available for real-time inference.
-
-
Prepares features for model training and real-time inference, as described in Chapter 4. Retrieving features for model training:
-
Makes features available to models.
-
Uses
feastPython APIs to retrieve features for model training and inference.
-
Setting up the Feature Store user interface for initial use
You can use a web-based user interface to simplify and accelerate the creation of model development features. This visual interface helps you explore and understand your Feature Store.
You can use the Feature Store UI to access a centralized catalog of features and metadata, such as transformation logic and materialization job status. You can also view features, manage entities, and use lineage and search capabilities.
You must enable the Feature Store UI before you can use it.
Prerequisites
-
You have Administrator access.
-
You have enabled the Feast Operator.
-
You have created a Feature Store CRD, as described in Creating a Feature Store instance in a project.
-
Your REST API server is running.
Procedure
-
Log in to the Open Data Hub Dashboard and click the Feature Store tab on the left navigation.
-
On the Overview page, click the create FeatureStore button.
-
Add YAML definitions to enable the user interface.
-
Edit the following label to enable the UI:
-
Label: -
feature-store-ui: enabled -
This creates a pod and initiates the service registry.
-
-
Click the options icon (⋮) and choose Start job.
-
Click on the Jobs tab and then Logs on the left navigation, to confirm that the CronJob is running.
-
Navigate to the Feature views tab on the left navigation, and you will be able to see your new UI.
Verification
Click Overview. If your Feature Store user interface was created, you see the following cards: * Entities * Data sources * Datasets * Features * Feature views * Feature services
Additional resources
Additional resources
-
For example Feature Store CRD configurations, see the Feast Operator configuration samples.
-
For details about the Feast CRD APIs, see the Feast API documentation.
-
For information on how to implement machine learning features, see the Feast documentation.
-
For end-to-end use case examples of how Feature Store can benefit your AI/ML workflows, see Feast Getting Started: Use Cases.
Configuring Feature Store
As a cluster administrator, you can install and manage Feature Store as a component in the Open Data Hub Operator configuration.
Setting up Feature Store
As a cluster administrator, you must complete the following tasks to set up Feature Store:
-
Enable the Feature Store component.
-
Create a project and add a Feature Store instance.
-
Initialize the Feature Store instance.
-
Set up Feature Store so that ML Engineers and data scientists can push and retrieve features to use for model training and inference.
Before you begin
Before you implement Feature Store in your machine learning workflow, you must have the following information:
- Knowledge of your data and use case
-
You must know your use case and your raw underlying data so that you can identify the properties or attributes that you want to define as features. For example, if you are developing machine learning (ML) models that detect possible credit card fraud transactions, you would identify data such as purchase history, transaction location, transaction frequency, or credit limit.
With Feature Store, you define each of those attributes as a feature. You group features that share a conceptual link or relationship together to define an entity. You define entities to map to the domain of your use case. Not all features must be in an entity.
- Knowledge of your data source
-
You must know the source of the raw data that you want to use in your ML workflow. When you configure the Feature Store online and offline stores and the feature registry, you must specify an environment that is compatible with the data source. Also, when you define features, you must specify the data source for the features.
Feature Store uses a time-series data model to represent data. This data model is used to interpret feature data in data sources in order to build training datasets or materialize features into an online store.
You can connect to the following types of data sources:
- Batch data source
-
A method of collecting and processing data in discrete chunks or batches, rather than continuously streaming it. This approach is commonly used for large datasets or when real-time processing is not essential. In a data processing context, a batch data source defines the connection to the data-at-rest source, allowing you to access and process data in batches. Examples of batch data sources include data warehouses (for example, BigQuery, Snowflake, and Redshift) or data lakes (for example, S3 and GCS). Typically, you define a batch data source when you configure the Feature Store offline store.
- Stream data source
-
The origin of data that is continuously flowing or emitted for online, real-time processing. Feature Store does not have native streaming integrations, but it facilitates push sources that allow you to push features into Feature Store. You can use Feature Store for training or batch scoring (offline), for real-time feature serving (online), or for both. Typically, you define a stream data source when you configure the Feature Store online store.
You can use the following data sources with Feature Store:
Data sources for online stores
-
SQLite
-
Snowflake
-
Redis
-
Dragonfly
-
IKV
-
Datastore
-
DynamoDB
-
Bigtable
-
PostgreSQL
-
Cassandra + Astra DB
-
Couchbase
-
MySQL
-
Hazelcast
-
ScyllaDB
-
Remote
-
SingleStore
For details on how to configure these online stores, see the Feast reference documentation for online stores.
Data sources for offline stores
-
Dask
-
Snowflake
-
BigQuery
-
Redshift
-
DuckDB
An offline store is an interface for working with historical time-series feature values that are stored in data sources. Each offline store implementation is designed to work only with the corresponding data source.
Offline stores are useful for the following purposes:
-
To build training datasets from time-series features.
-
To materialize (load) features into an online store to serve those features at low-latency in a production setting.
You can use only a single offline store at a time. Offline stores are not compatible with all data sources; for example, the BigQuery offline store cannot be used to query a file-based data source.
For details on how to configure these offline stores, see the Feast reference documentation for offline stores.
Data sources for the feature registry
-
Local
-
S3
-
GCS
-
SQL
-
Snowflake
For details on how to configure these registry options, see the Feast reference documentation for the registry.
Enabling the Feature Store component
To allow the ML engineers and data scientists in your organization to work with machine learning features, you must enable the Feature Store component in Open Data Hub.
Prerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have installed Open Data Hub.
Procedure
-
In the OpenShift Container Platform console, click Operators → Installed Operators.
-
Click the Open Data Hub Operator.
-
Click the Data Science Cluster tab.
-
Click the default instance name (for example, default-dsc) to open the instance details page.
-
Click the YAML tab.
-
Edit the
spec:componentssection. For thefeastoperatorcomponent, set themanagementStatefield toManaged:spec: components: feastoperator: managementState: Managed -
Click Save.
Verification
Check the status of the feast-operator-controller-manager-<pod-id> pod:
-
Click Workloads → Deployments.
-
From the Project list, select redhat-ods-applications.
-
Search for the feast-operator-controller-manager deployment.
-
Click the feast-operator-controller-manager deployment name to open the deployment details page.
-
Click the Pods tab.
-
View the pod status.
When the status of the feast-operator-controller-manager-<pod-id> pod is Running, Feature Store is enabled.
Next Step
-
Create a Feature Store instance in a project.
Creating a Feature Store instance in a project
You can add an instance of Feature Store to a project by creating a custom resource definition (CRD) in the OpenShift console.
The following example shows the minimum requirements for a Feature Store CR YAML file:
apiVersion: feast.dev/v1alpha1
kind: FeatureStore
metadata:
name: sample
spec:
feastProject: my_feast_projectPrerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have enabled the Feature Store component, as described in Enabling the Feature Store component.
-
You have set up your database infrastructure for the online store, offline store, and registry.
For an example of setting up and running PostgreSQL (for the registry) and Redis (for the online store), see the Feature Store Operator quick start example: https://github.com/feast-dev/feast/tree/stable/examples/operator-quickstart.
-
You have created a project, as described in Creating a project. In the following procedure,
my-projectis the name of the project.
Procedure
-
In the OpenShift console, click the Quick Create (
 ) icon and then click the Import YAML option.
) icon and then click the Import YAML option. -
Verify that your project is the selected project.
-
Copy the following code and paste it into the YAML editor:
apiVersion: feast.dev/v1alpha1 kind: FeatureStore metadata: name: sample-git spec: feastProject: credit_scoring_local feastProjectDir: git: url: https://github.com/feast-dev/feast-credit-score-local-tutorial ref: 598a270The
spec.feastProjectDirreferences a Feature Store project that is in the Git repository for a Credit Store tutorial. -
Optionally, change the
metadata.namefor the Feature Store instance. -
Optionally, edit
feastProject, which is the namespace for organizing your Feature Store instance. Note that this project is not the Open Data Hub project. -
Click Create.
When you create the Feature Store CR in OpenShift, Feature Store starts a remote online feature server, and configures a default registry and an offline store with the local provider.
A provider is a customizable interface that provides default Feature Store components, such as the registry, offline store, and online store, that target a specific environment, ensuring that these components can work together seamlessly. The local provider uses the following default settings:
-
Registry: A SQL registry or local file
-
Offline store: A Parquet file
-
Online store: SQLite
Verification
-
In the OpenShift Container Platform console, select Workloads → Pods.
-
Make sure that your project (for example, my-project) is selected.
-
Find the pod that has the
feast-prefix, followed by themetadata.namethat you specified in the CRD configuration, for example,sample-git. -
Verify that the pod status is Running.
-
Click the
feastpod and then select Pod details. -
Scroll down to see the online container. This container is the deployment for the online server. It makes the feature server REST API available in the OpenShift cluster.
-
Scroll up and then click Terminal.
-
Run the following command to verify that the
feastCLI is installed correctly:$ feast --help
-
To view the files for the Feature Store project, enter the following command:
$ ls -la
You should see output similar to the following:
. .. data example_repo.py feature_store.yaml __init__.py __pycache__ test_workflow.py -
To view the
feature_store.yamlconfiguration file, enter the following command:$ cat feature_store.yaml
You should see output similar to the following:
project: my_feast_project provider: local online_store: path: /feast-data/online_store.db type: sqlite registry: path: /feast-data/registry.db registry_type: file auth: type: no_auth entity_key_serialization_version: 3
The feature_store.yaml file defines the following components:
-
project — The namespace for the Feature Store instance. Note that this project refers to the feature project rather than the Open Data Hub project.
-
provider — The environment in which Feature Store deploys and operates.
-
registry — The location of the feature registry.
-
online_store — The location of the online store.
-
auth - The type of authentication and authorization (
no_auth,kubernetes, oroidc) -
entity_key_serialization_version - Specifies the serialization scheme that Feature Store uses when writing data to the online store.
NOTE: Although the offline_store location is not included in the feature_store.yaml file, the Feature Store instance uses a DASK file-based offline store. In the feature_store.yaml file, the registry type is file but it uses a simple SQLite database.
Next steps
-
Optionally, you can customize the default configurations for the offline store, online store, or registry by editing the YAML configuration for the Feature Store CR, as described in Customizing your Feature Store configuration.
-
Give your ML engineers and data scientists access to the project so that they can create a workbench. and provide them with a copy of the
feature_store.yamlfile so that they can add it to their workbench IDE, such as Jupyter.
Configuring and managing Role Based Access Control
You can set permissions using Role-Based Access Control (RBAC) to manage user access to Feature Store. This grants access to actions such as creating, reading, updating and deleting namespaces.
Prerequisites
-
You have Administrator access.
-
You have created a Feature Store instance.
|
Note
|
For more information, see What is Kubernetes Role Based Access Control? |
Procedure
-
Open your command line interface (CLI). Deploy the Feature store custom resource by running the following command:
kubectl apply -f feature-store-cr.yaml-
Locate the Feature Store Custom Resource (CR) YAML file, which is named feature-store-cr.yaml. You will see key value pairs. Change the key type: to Kubernetes:
apiVersion: feast.dev/v1alpha1 kind: FeatureStore metadata: name: <feature-store-name> spec: # ... other configurations ... authz: type: Kubernetes
-
-
Verify that your Feature Store projects were created.
kubectl get feast <project name> kubectl get configmaps -l feast.dev/service-type=client <your-project-name> <feast project name> <number of data entries> <time since created> -
Configure data science project permissions. You must create a
permissions.pyfile in the Feature Store pod terminal. This file must reside in thefeature_store directory.You can use a role based policy, a group based policy, combined group namespace policy or read and write permissions.NoteFor an example of a
permission.pyfile, see the Feast Operator RBAC with TLS. -
Transfer your local
permissions.pyfile to the remote container filesystem. In a Kubernetes/OpenShift Container Platform environment, you use a command-line tool such as oc OpenShift Container Platform Command Line Interface or kubectl:`oc/kubectl cp <local-file> <remote-pod>:<remote-path>.` -
Configure and set up the Feature Store Server. If a cron job has been run previously, run feast apply on the online container. Open your command line interface (CLI) and run the following command:
`oc create job --from=cronjob/feast-project-name cronjob-manual-$(date +%s) -n <project name>` `oc exec -it deployments/<feast deployment name> -c online -- feast apply` -
Configure authentication in the OpenShift Container Platform web console. You have full control over your data science project access. You can grant and revoke access to users/groups instantly.
-
Log in to your Open Data Hub or OpenShift Container Platform Console.
-
Navigate to the Data Science Projects tab and select the appropriate project.
-
Click Permissions tab > Users Groups.
-
Name your group.
-
Under Permissions, choose a predefined role, add permissions, and click Save.
-
|
Note
|
The name of your group must exist in your identity provider. The identity provider is configured at the OpenShift Container Platform cluster level, outside of the specific project you are working in. |
Verification
The deployment pod is running and you see the project details in the Feature Store UI and Integration tab.
Additional resources
Adding feature definitions and initializing your Feature Store instance
Initialize the Feature Store instance to start using it.
When you initialize the Feature Store instance, Feature Store completes the following tasks:
-
Scans the Python files in your feature repository and finds all Feature Store object definitions, such as feature views, entities, and data sources.
Note: Feature Store reads all Python files recursively, including subdirectories, even if they do not contain feature definitions. For information on identifying Python files, such as imperative scripts that you want Feature Store to ignore, see Specifying files to ignore.
-
Validates your feature definitions, for example, by checking for uniqueness of features within a feature view.
-
Syncs the metadata about objects to the feature registry. If a registry does not exist, Feature Store creates one. The default registry is a simple Protobuf binary file on disk (locally or in an object store).
-
Creates or updates all necessary Feature Store infrastructure. The exact infrastructure that Feature Store creates depends on the provider configuration that you have set in
feature_store.yaml. For example, when you specifylocalas your provider, Feature Store creates the infrastructure on the local cluster.Note: When you use a cloud provider, such as Google Cloud Platform or Amazon Web Service, the
feast applycommand creates cloud infrastructure that might incur costs for your organization.
Prerequisites
-
An ML engineer on your team has given you a Python file that defines features. For more information about how to define features, see Defining features.
-
If you want to store the feature registry in cloud storage or in a database, you have configured storage for the feature registry. For example, if the provider is GCP, you have created a Cloud Storage bucket for the feature registry.
-
You have the
cluster-adminrole in OpenShift Container Platform. -
You have created a Feature Store instance in your project.
Procedure
-
In the OpenShift console, select Workloads → Pods.
-
Make sure that your project is the current project.
-
Click the
feastpod and then select Pod details. -
Scroll down to see the online container. This container is the deployment for the online server, and it makes the feature server REST API available in the OpenShift cluster.
-
Scroll up and then click Terminal.
-
Copy the feature definition (
.py) file to your Feature Store directory. -
To create a feature registry and add the feature definitions to the registry, run the following command:
feast apply
Verification
-
You should see output similar to the following that indicates that the features in the feature definition file were successfully added to the registry:
Created project credit_scoring_local Created entity zipcode Created entity dob_ssn Created feature view zipcode_features Created feature view credit_history Created on demand feature view total_debt_calc Created sqlite table credit_scoring_local_credit_history Created sqlite table credit_scoring_local_zipcode_features
-
In the OpenShift console, select Workloads → Deployments to view the deployment pod.
Specifying files to ignore
When you run the feast apply command, Feature Store reads all Python files recursively, including Python files in subdirectories, even if the Python files do not contain feature definitions.
If you have Python files, such as imperative scripts, in your registry folder that you want Feature Store to ignore when you run the feast apply command, you should create a .feastignore file and add a list of paths to all files that you want Feature Store to ignore.
Example .feastignore file
# Ignore virtual environment venv # Ignore a specific Python file scripts/foo.py # Ignore all Python files directly under scripts directory scripts/*.py # Ignore all "foo.py" anywhere under scripts directory scripts/**/foo.py
Viewing Feature Store objects in the web-based UI
You can use the Feature Store Web UI to view all registered features, data sources, entities, and feature services.
Prerequisites
-
You can access the OpenShift console.
-
You have installed the OpenShift CLI (
oc) as described in the appropriate documentation for your cluster:-
Installing the OpenShift CLI for OpenShift Container Platform
-
Installing the OpenShift CLI for Red Hat OpenShift Service on AWS
-
-
You have enabled the Feature Store component, as described in Enabling the Feature Store component.
-
You have created a Feature Store CRD, as described in Creating a Feature Store instance in a project.
Procedure
-
In the OpenShift console, select Administration → CustomResourceDefinitions.
-
To filter the list, in the Search by Name field, enter feature.
-
Click the FeatureStore CRD and then click Instances.
-
Click the name of the instance that corresponds to the metadata name you specified when you created the Feature Store instance.
-
Edit the YAML to include a reference to
services.uiin thespecsection, as shown in the following example:spec: feastProject: credit_scoring_local feastProjectDir: git: ref: 598a270 url: 'https://github.com/feast-dev/feast-credit-score-local-tutorial' services: ui: {} -
Click Save and then click Reload.
The Feature Store Operator starts a container for the web-based Feature Store UI and creates an OpenShift route that provides the URL so that you can access it.
-
In the OpenShift Container Platform console, select Workloads → Pods.
-
Make sure that your project (for example,
my-project) is selected.You should see a deployment for the web-based UI. Note that OpenShift enables TLS by default at runtime.
-
To populate the web-based UI with the objects in your Feature Store instance:
-
In the OpenShift console, select Workloads → Pods.
-
Make sure that your project (for example,
my-project) is selected. -
Click the
feastpod and then select Pod details. -
Click Terminal.
-
To update the Feature Store instance, enter the following command:
feast apply
-
-
To find the URL for the Feature Store UI, in the OpenShift console, click Networking → Routes.
In the row for the Feature Store UI, for example
feast-sample-ui, the URL is in the Location column. -
Click the URL link to open it in your default web browser.
Verification
The Feature Store Web UI is displayed and shows the feature objects in your project as shown in the following figure:
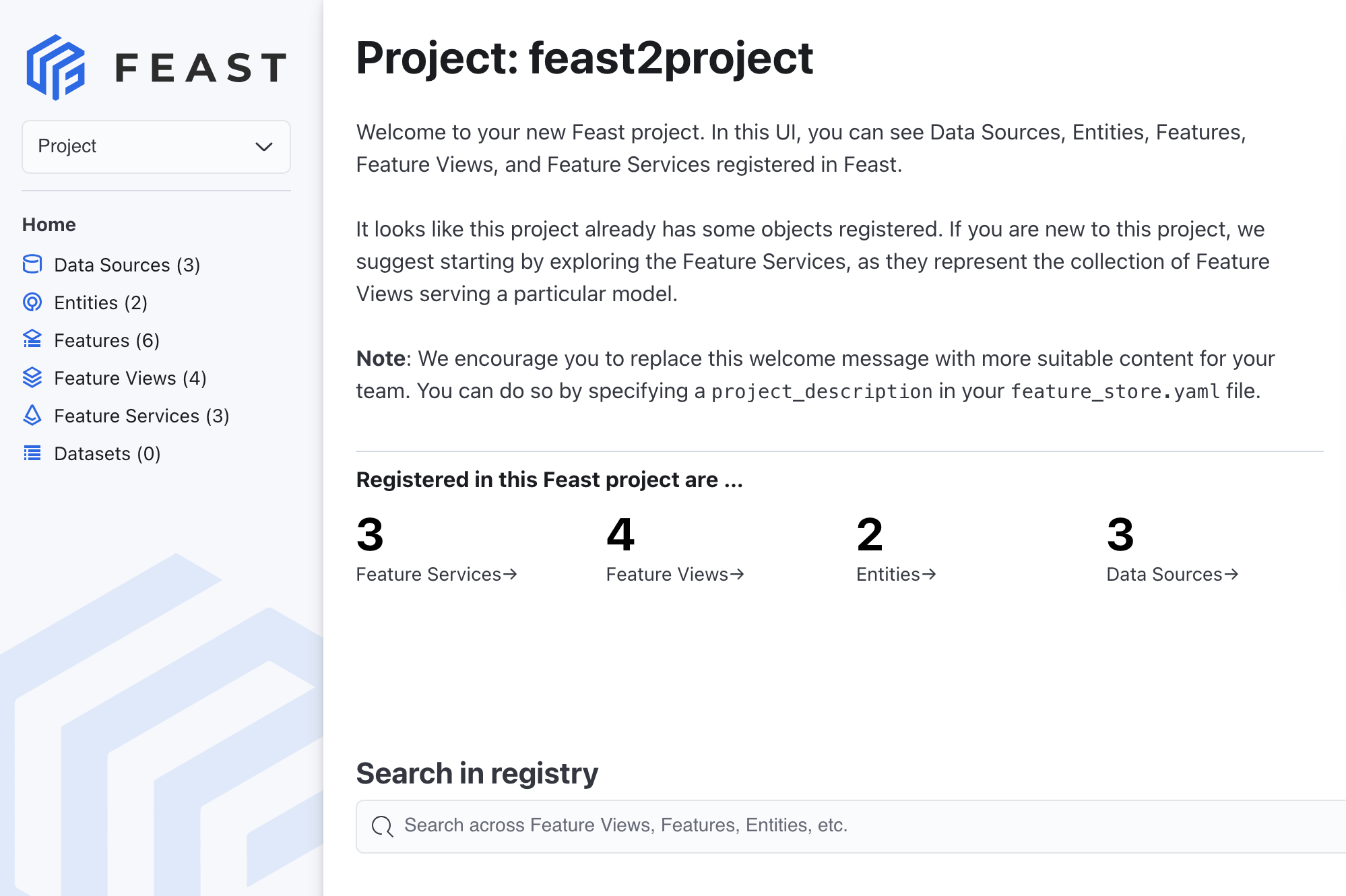
Figure 2. The Feature Store Web UI
Customizing your Feature Store configuration
Optionally, you can apply the following configurations to your Feature Store instance:
-
Configure an offline store
-
Configure an online store
-
Configure the feature registry
-
Configure persistent volume claims (PVCs)
-
Configure role-based access control (RBAC)
The examples in the following sections describe how to customize a Feature Store instance by creating a new custom resource definition (CRD). Alternatively, you can customize an existing feature instance as described in Editing an existing Feature Store instance.
For more information about how you can customize your Feature Store configuration, see the Feast API documentation.
Configuring an offline store
When you create a Feature Store instance that uses the minimal configuration, by default, Feature Store uses a SQLite file-based store for the offline store.
The example in the following procedure shows how to configure DuckDB for the offline store.
You can configure other offline stores, such as Snowflake, BigQuery, Redshift, as detailed in the Feast reference documentation for offline stores.
|
Note
|
The example code in the following procedure requires that you edit it with values that are specific to your use case. |
Prerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have enabled the Feature Store component, as described in Enabling the Feature Store component.
-
You have created a project, as described in Creating a project. In the following procedure,
my-projectis the name of the project. -
Your project includes an existing secret that provides credentials for accessing the database that you want to use for the offline store. The example in the following procedure requires that you have configured DuckDB.
Procedure
-
In the OpenShift console, click the Quick Create (
) icon and then click the Import YAML option. -
Verify that your project is the selected project.
-
Copy the following code and paste it into the YAML editor:
apiVersion: feast.dev/v1alpha1 kind: FeatureStore metadata: name: sample-db-persistence spec: feastProject: my_project services: offlineStore: persistence: file: type: duckdb -
Edit the
services.offlineStoresection to specify values specific to your use case. -
Click Create.
Verification
-
In the OpenShift Container Platform console, select Workloads → Pods.
-
Make sure that your project (for example,
my-project) is selected. -
Find the pod that has the
feast-prefix, followed by the metadata name that you specified in the CRD configuration, for example,feast-sample-db-persistence. -
Verify that the status is Running.
Configuring an online store
When you create a Feature Store instance using the minimal configuration, by default, the online store is a SQLite database.
The example in the following procedure shows how to configure a PostgreSQL database for the online store.
You can configure other online stores, such as Snowflake, Redis, and DynamoDB, as detailed in the Feast reference documentation for online stores.
|
Note
|
The example code in the following procedure requires that you edit it with values that are specific to your use case. |
Prerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have enabled the Feature Store component, as described in Enabling the Feature Store component.
-
You have created a project, as described in Creating a project. In the following procedure,
my-projectis the name of the project. -
Your project includes an existing secret that provides credentials for accessing the database that you want to use for the online store. The example in the following procedure requires that you have configured a PostgreSQL database.
Procedure
-
In the OpenShift console, click the Quick Create (
) icon and then click the Import YAML option. -
Verify that your project is the selected project.
-
Copy the following code and paste it into the YAML editor:
apiVersion: feast.dev/v1alpha1 kind: FeatureStore metadata: name: sample-db-persistence spec: feastProject: my_project services: onlineStore: persistence: store: type: postgres secretRef: name: feast-data-stores -
Edit the
services.onlineStoresection to specify values that are specific to your use case. -
Click Create.
Verification
-
In the OpenShift Container Platform console, select Workloads → Pods.
-
Make sure that your project (for example,
my-project) is selected. -
Find the pod that has the
feast-prefix, followed by the metadata name that you specified in the CRD configuration, for example,feast-sample-db-persistence. -
Verify that the status is Running.
Configuring the feature registry
By default, when you create a feature instance using the minimal configuration, the registry is a simple SQLite database.
The example in the following procedure shows how to configure an S3 registry.
You can configure other types of registries, such as GCS, SQL, Snowflake, as detailed in the Feast reference documentation for registries.
|
Note
|
The example code in the following procedure requires that you edit it with values that are specific to your use case. |
Prerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have enabled the Feature Store component, as described in Enabling the Feature Store component.
-
You have created a project, as described in Creating a project. In the following procedure,
my-projectis the name of the project. -
Your project includes an existing secret that provides credentials for accessing the database that you want to use for the registry. The example in the following procedure requires that you have configured S3.
Procedure
-
In the OpenShift console, click the Quick Create (
) icon and then click the Import YAML option. -
Verify that your project is the selected project.
-
Copy the following code and paste it into the YAML editor:
apiVersion: feast.dev/v1alpha1 kind: FeatureStore metadata: name: sample-s3-registry spec: feastProject: my_project services: registry: local: persistence: file: path: s3://bucket/registry.db s3_additional_kwargs: ServerSideEncryption: AES256 ACL: bucket-owner-full-control CacheControl: max-age=3600 -
Edit the
services.registrysection to specify values that are specific to your use case. -
Click Create.
Verification
-
In the OpenShift Container Platform console, select Workloads → Pods.
-
Make sure that your project (for example,
my-project) is selected. -
Find the pod that has the
feast-prefix, followed by the metadata name that you specified in the CRD configuration, for example,sample-s3-registry. -
Click the feast pod and then select Pod details.
-
Click Terminal.
-
In the Terminal window, enter the following command to view the configuration, including the S3 registry:
$ cat feature_store.yaml
Example PVC configuration
When you configure the online store, offline store, or registry, you can also configure persistent volume claims (PVCs) as shown in the following Feature Store custom resource definition (CRD) example.
|
Note
|
The following example code requires that you edit it with values that are specific to your use case. |
apiVersion: feast.dev/v1alpha1
kind: FeatureStore
metadata:
name: sample-pvc-persistence
spec:
feastProject: my_project
services:
onlineStore: # (1)
persistence:
file:
path: online_store.db
pvc:
ref:
name: online-pvc
mountPath: /data/online
offlineStore: # (2)
persistence:
file:
type: duckdb
pvc:
create:
storageClassName: standard
resources:
requests:
storage: 5Gi
mountPath: /data/offline
registry: # (3)
local:
persistence:
file:
path: registry.db
pvc:
create: {}
mountPath: /data/registry
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: online-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi-
The online store specifies a PVC that must already exist.
-
The offline store specifies a storage class name and storage size.
-
The registry configuration specifies that the Feature Store Operator creates a PVC with default settings.
Editing an existing Feature Store instance
The examples in this document describe how to customize a Feature Store instance by creating a new custom resource definition (CRD). Alternatively, you can customize an existing feature instance.
Prerequisites
-
You have cluster administrator privileges for your OpenShift Container Platform cluster.
-
You have created a Feature Store instance, as described in Deploying a Feature Store instance in a project.
Procedure
-
In the OpenShift console, select Administration → CustomResourceDefinitions.
-
To filter the list, in the Search by Name field, enter feature.
-
Click the FeatureStore CRD and then click Instances.
-
Select the instance that you want to edit, and then click YAML.
-
In the YAML editor, edit the configuration.
-
Click Save and then click Reload.
Verification
The Feature Store instance CRD deploys successfully.
Defining machine learning features
As part of the Feature Store workflow, ML engineers or data scientists are responsible for identifying data sources and defining features of interest.
Setting up your working environment
You must set up your Open Data Hub working environment so that you can use features in your machine learning workflow.
Prerequisites
-
You have access to the Open Data Hub project in which your cluster administrator has set up the Feature Store instance.
Procedure
-
From the Open Data Hub dashboard, click Projects.
-
Click the name of the project in which your cluster administrator has set up the Feature Store instance.
-
In the project in which the cluster administrator set up Feature Store, create a workbench, as described in Creating a workbench.
-
To open the IDE (for example, JuypterLab), in a new window, click the open icon (
 ) next to the workbench.
) next to the workbench. -
Add a
feature_store.yamlfile to your notebook environment. For example, upload a local file or clone a Git repo that contains the file, as described in Uploading an existing notebook file to JupyterLab from a Git repository by using the CLI. -
Open a new Python notebook.
-
In a cell, run the following command to install the
feastCLI:! pip install feast
Verification
-
Run the following command to list the available features:
! feast features list
The output should show a list of features, Feature View and data type similar to the following:
Feature Feature View Data Type credit_card_due credit_history Int64 mortgage_due credit_history Int64 student_loan_due credit_history Int64 vehicle_loan_due credit_history Int64 city zipcode_features String state zipcode_features String location_type zipcode_features String
-
Optionally, run the following commands to list the registered feast projects, feature views, and entities.
! feast projects list ! feast feature-views list ! feast entities list
Enabling automatic authentication and publishing features
Enable automatic, write access authentication for specific projects.
Prerequisites
-
Your Feature Store has been deployed.
-
User Access permissions have been configured.
Procedure
-
From the Open Data Hub dashboard, click Projects.
The Projects page opens.
-
Click the name of the project that you want to work on.
-
Create a new workbench or open an existing workbench with the Feast software development kit (SDK).
-
In the Feature Store client configuration table, select configmaps associated with the desired repositories.
-
Copy the Python script that is generated on the left of the page.
-
Click the Workbenches tab and launch a workbench.
-
Paste the Python script into the workbench cell.
-
|
Note
|
Feast SDK is available in all images except minimal. |
Verification
If the procedure is successful, you will be able to create a new feature, or access existing feature store objects, such as feature views.
About feature definitions
A machine learning feature is a measurable property or field within a data set that a machine learning model can analyze to learn patterns and make decisions. In Feature Store, you define a feature by defining the name and data type of a field.
A feature definition is a schema that includes the field name and data type, as shown in the following example:
from feast import Field
from feast.types import Int64
credit_card_amount_due = Field(
name="credit_card_amount_due",
dtype=Int64
)For a list of supported data types for fields in Feature Store, see the feast.types module in the Feast documentation.
In addition to field name and data type, a feature definition can include additional metadata, specified as descriptions of features, as shown in the following example:
from feast import Field
from feast.types import Int64
credit_card_amount_due = Field(
name="credit_card_amount_due",
dtype=Int64,
description="Credit card amount due for user",
tags={"team": "loan_department"},
)Specifying the data source for features
As an ML engineer or a data scientist, you must specify the data source for the features that you want to define.
The data source differs depending on whether you are using an offline store, for batch data and training data sets, or an online store, for model inference. Optionally, you can use a Parquet or a Delta-formatted file as the data source. You can specify a local file or a file in storage, such as Amazon Simple Storage Service (S3).
For offline stores, specify a batch data source. You can specify a data warehouse, such as BigQuery, Snowflake, Redshift, or a data lake, such as Amazon S3 or Google Cloud Platform (GCP). You can use Feature Store to ingest and query data across both types of data sources.
For online stores, specify a database backend, such as Redis, GCP Datastore, or DynamoDB.
Prerequisites
-
You know the location of the data source for your ML workflow.
Procedure
-
In the editor of your choice, create a new Python file.
-
At the beginning of the file, specify the data source for the features that you want to define within the file.
For example, use the following code to specify the data source as a Parquet-formatted file:
from feast import FileSource from feast.data_format import ParquetFormat parquet_file_source = FileSource( file_format=ParquetFormat(), path="file:///feast/customer.parquet", ) -
Save the file.
About organizing features by using entities
Within a feature view, you can group features that share a conceptual link or relationship together to define an entity. You can think of an entity as a primary key that you can use to fetch features. Typically, an entity maps to the domain of your use case. For example, a fraud detection use case could have customers and transactions as their entities, with group-related features that correspond to these customers and transactions.
A feature does not have to be associated with an entity. For example, a feature of a customer entity could be the number of transactions they have made on an average month, while a feature that is not observed on a specific entity could be the total number of transactions made by all users in the last month.
customer = Entity(name='dob_ssn', join_keys=['dob_ssn'])The entity name uniquely identifies the entity. The join key identifies the physical primary key on which feature values are joined together for feature retrieval.
The following table shows example data with a single entity column (dob_ssn) and two feature columns (credit_card_due and bankruptcies).
| row | timestamp | dob_ssn | credit_card_due | bankruptcies |
|---|---|---|---|---|
1 |
5/22/2025 0:00:00 |
19530219_5179 |
833 |
0 |
2 |
5/22/2025 0:00:00 |
19500806_6783 |
1297 |
0 |
3 |
5/22/2025 0:00:00 |
19690214_3370 |
3912 |
1 |
4 |
5/22/2025 0:00:00 |
19570513_7405 |
8840 |
0 |
Creating feature views
You define features within a feature view. A feature view is an object that represents a logical group of time-series feature data in a data source. Feature views indicate to Feature Store where to find your feature values, for example, in a parquet file or a BigQuery table.
By using feature views, you define the existing feature data in a consistent way for both an offline environment, when you train your models, and an online environment, when you want to serve features to models in production.
Feature Store uses feature views during the following tasks:
-
Generating training datasets by querying the data source of feature views to find historical feature values. A single training data set can consist of features from multiple feature views.
-
Loading feature values into an online or offline store. Feature views determine the storage schema in the online or offline store. Feature values can be loaded from batch sources or from stream sources.
-
Retrieving features from the online or offline store. Feature views provide the schema definition for looking up features from the online or offline store.
When you create a feature project, the feature_repo subfolder includes a Python file that includes example feature definitions (for example, example_features.py) .
To define new features, you can edit the code in the example file or add a new file to the feature repository.
Note: Feature views only work with timestamped data. If your data does not contain timestamps, insert dummy timestamps. The following example shows how to create a table with dummy timestamps for PostgreSQL-based data:
CREATE TABLE employee_metadata (
employee_id INT PRIMARY KEY,
department TEXT,
dummy_event_timestamp TIMESTAMP DEFAULT '2024-01-01'
);
INSERT INTO employee_metadata (employee_id, department)
VALUES (1, 'Advanced'), (2, 'New');Prerequisites
-
You know what data is relevant to your use case.
-
You have identified attributes in your data that you want to use as features in your ML models.
Procedure
-
In your IDE, such as JupyterLab, open the
feature_repo/example_features.pyfile that contains example feature definitions or create a new Python (.py) file in thefeature_repodirectory. -
Create a feature view that is relevant to your use case based on the structure shown in the following example:
credit_history_source = FileSource( (1) name="Credit history", path="data/credit_history.parquet", file_format=ParquetFormat(), timestamp_field="event_timestamp", created_timestamp_column="created_timestamp", ) credit_history = FeatureView( (2) name="credit_history", entities=[dob_ssn], (3) ttl=timedelta(days=90), (4) schema=[ (5) Field(name="credit_card_due", dtype=Int64), Field(name="mortgage_due", dtype=Int64), Field(name="student_loan_due", dtype=Int64), Field(name="vehicle_loan_due", dtype=Int64), Field(name="hard_pulls", dtype=Int64), Field(name="missed_payments_2y", dtype=Int64), Field(name="missed_payments_1y", dtype=Int64), Field(name="missed_payments_6m", dtype=Int64), Field(name="bankruptcies", dtype=Int64), ], source=credit_history_source, (6) tags={"origin": "internet"}, (7) )-
A data source that provides time-stamped tabular data. A feature view must always have a data source for the generation of training datasets and when materializing feature values into the online store. Possible data sources are batch data sources from data warehouses (BigQuery, Snowflake, Redshift), data lakes (S3, GCS), or stream sources. Users can push features from data sources into Feature Store, and make the features available for training or batch scoring ("offline"), for realtime feature serving ("online"), or both.
-
A name that identifies the feature view in the project. Within a feature view, feature names must be unique.
-
Zero or more entities. Feature views generally contain features that are properties of a specific object, in which case that object is defined as an entity and included in the feature view. If the features are not related to a specific object, the feature view might not have entities.
-
(Optional) Time-to-live (TTL) to limit how far back to look when Feature Store generates historical datasets.
-
One or more feature definitions.
-
A reference to the data source.
-
(Optional) You can add metadata, such as tags that enable filtering of features when viewing them in the UI, listing them by using a CLI command, or by querying the registry directly.
-
-
Save the file.
Retrieving features for model training
Retrieving data science features
You can connect to the Feature Store and consume the features necessary for model development and inference.
Prerequisites
-
Your Feature Store has been deployed.
-
User access permissions have been configured by the administrator.
-
You have access to a relevant project and a workbench.
-
Your Feature Store client configuration must be complete.
Procedure
-
From the Open Data Hub dashboard, click Projects.
The Projects page opens.
-
Click the name of the project that you want to work on.
-
Create a new workbench or open an existing workbench with the Feast software development kit (SDK).
-
In the Feature Store client configuration table, select the configmaps associated with the desired repositories.
-
Copy the Python script that is generated on the left side of the page. that is generated on the left of the page.
-
Click the Workbenches tab and launch a workbench.
-
Paste the Python script into the workbench cell.
-
|
Note
|
|